
흩어진 업무 데이터와 시스템 로그로 발생하는 데이터 사일로 문제를 해결하기 위해 AWS 클라우드 환경에서 통합 AIOps 플랫폼과 RAG 시스템을 설계하고 구축한 과정을 기록합니다. 중앙 데이터 레이크, 지능형 검색 시스템, 운영 자동화를 통해 어떻게 전사적 정보 접근성과 운영 효율성을 높였는지 상세히 다룹니다.
흩어진 데이터를 연결하는 여정: 통합 AIOps 플랫폼 구축 회고
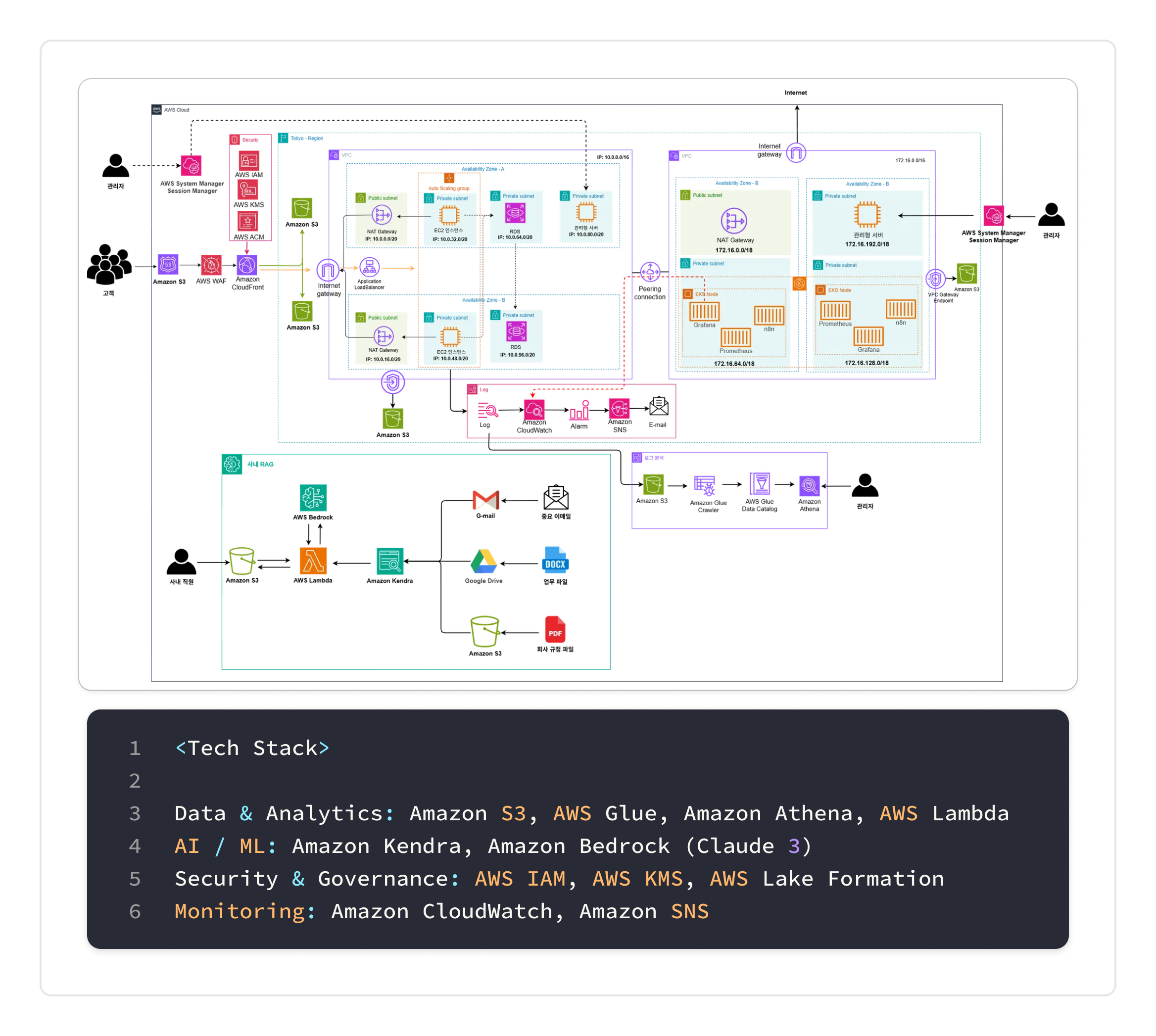
이번 프로젝트를 마무리하며 돌이켜보면, 우리가 얻고자 했던 궁극적인 결론은 ‘연결’을 통해 ‘가치’를 만드는 것이었다. 기술적으로는 파편화된 전사 데이터 자산을 AWS 기반의 단일 플랫폼으로 통합하고, 비즈니스적으로는 흩어진 정보와 로그 속에서 실질적인 효율성을 창출하는 통합 AIOps 플랫폼과 RAG 시스템을 구축하는 것. 이 과정은 단순히 여러 AWS 서비스를 조합하는 것을 넘어, 데이터의 흐름을 설계하고 거버넌스를 수립하며, 최종적으로 지능형 서비스까지 연결하는 엔드투엔드 아키텍처를 온전히 고민하고 구축하는 경험이었다.
왜 이 여정을 시작해야만 했는가
이번 프로젝트를 시작하며, 저는 하나의 가상 시나리오를 설정했다. 바로 데이터가 심각한 사일로(Silo) 상태에 놓인 어느 조직을 상상하는 것이었다. 이 가상의 조직에서는, 핵심적인 업무 지식이 PDF, DOCX 파일 형태로 개인의 구글 드라이브나 로컬 스토리지에 흩어져 있고, 다른 한쪽에서는 시스템 운영에 필수적인 VPC Flow Logs, WAF, ALB 로그 등이 각기 다른 서비스와 위치에 파편화되어 쌓여가는 상황을 가정했다. 직원들 사이에서는 간단한 정보조차 찾기 어렵다는 불만이 터져 나오는 배경이다.
이러한 데이터의 단절이 어떤 결과를 낳을지는 명백했다. 첫째, 사내 구성원들은 필요한 문서를 찾기 위해 여러 시스템을 전전하며 귀한 시간을 낭비하게 된다. 둘째, 엔지니어들은 장애가 발생했을 때 원인 분석을 위해 여러 로그 저장소를 일일이 뒤져야만 한다. 결국 신속한 대응은 고사하고, 파편화된 데이터로는 선제적인 위협 탐지나 패턴 분석조차 불가능한 구조적 한계에 부딪히게 되는 것이다. 따라서 내가 해결해야 할 과제는, 바로 이 가상의 시나리오 속 데이터 파편화 문제를 근본적으로 해결하고, 통합된 환경에서 누구나 쉽고 빠르게 정보를 얻을 수 있는 시스템을 구축하는 것이었다.
어떻게 문제를 해결해 나갔는가
목표는 명확했다. 모든 데이터가 흐르는 ‘호수’를 만들고, 그 호수 위에서 지능적인 ‘탐색’과 ‘자동화’가 가능하도록 하는 것. 이 목표를 달성하기 위해 나는 크게 네 가지 축으로 아키텍처를 설계하고 구현해 나갔다.
첫 번째 축은 사용 목적에 따라 명확히 구분된 웹 서비스 아키텍처 구축이었다.
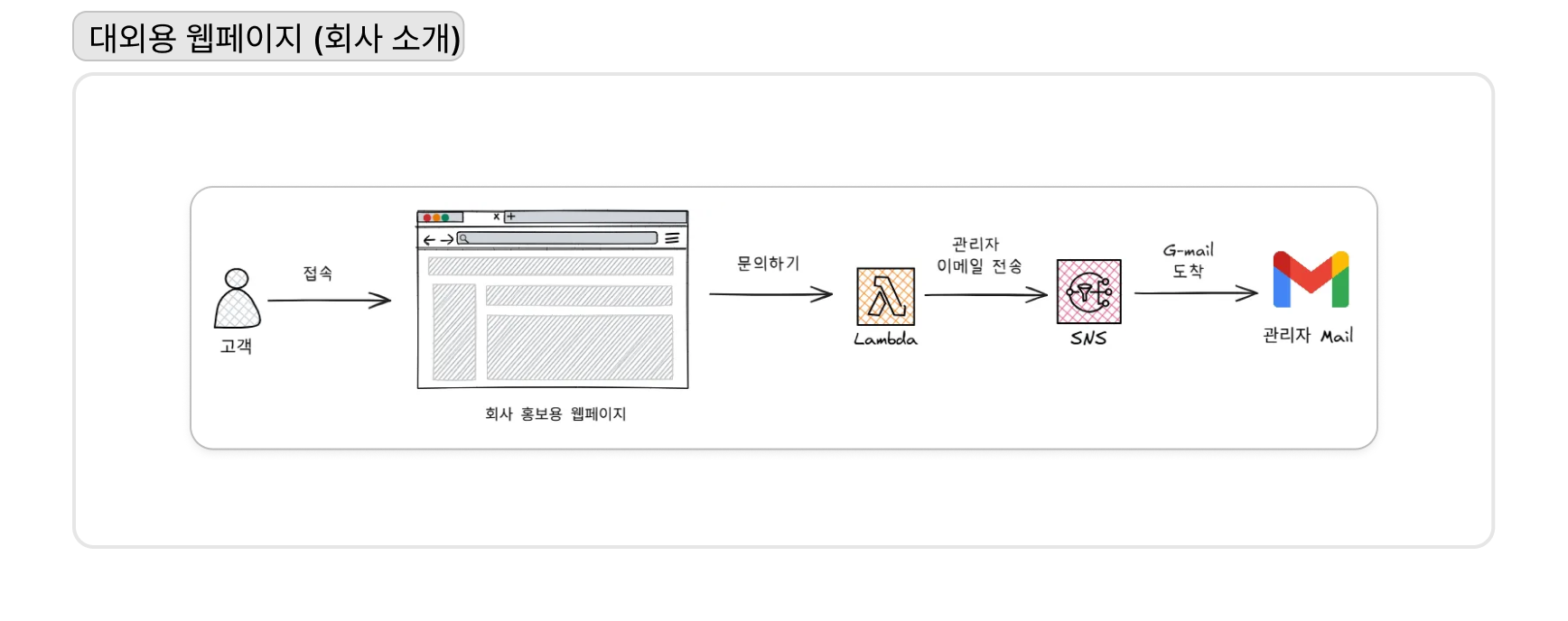
먼저, 대외용 서비스는 성격에 따라 아키텍처를 분리했다. 회사 홍보용 정적 웹사이트(WebA)는 S3에 콘텐츠를 호스팅하고 Amazon CloudFront를 통해 전 세계 사용자에게 빠르고 저렴하게 제공하는 완전한 서버리스 구조를 채택했다.
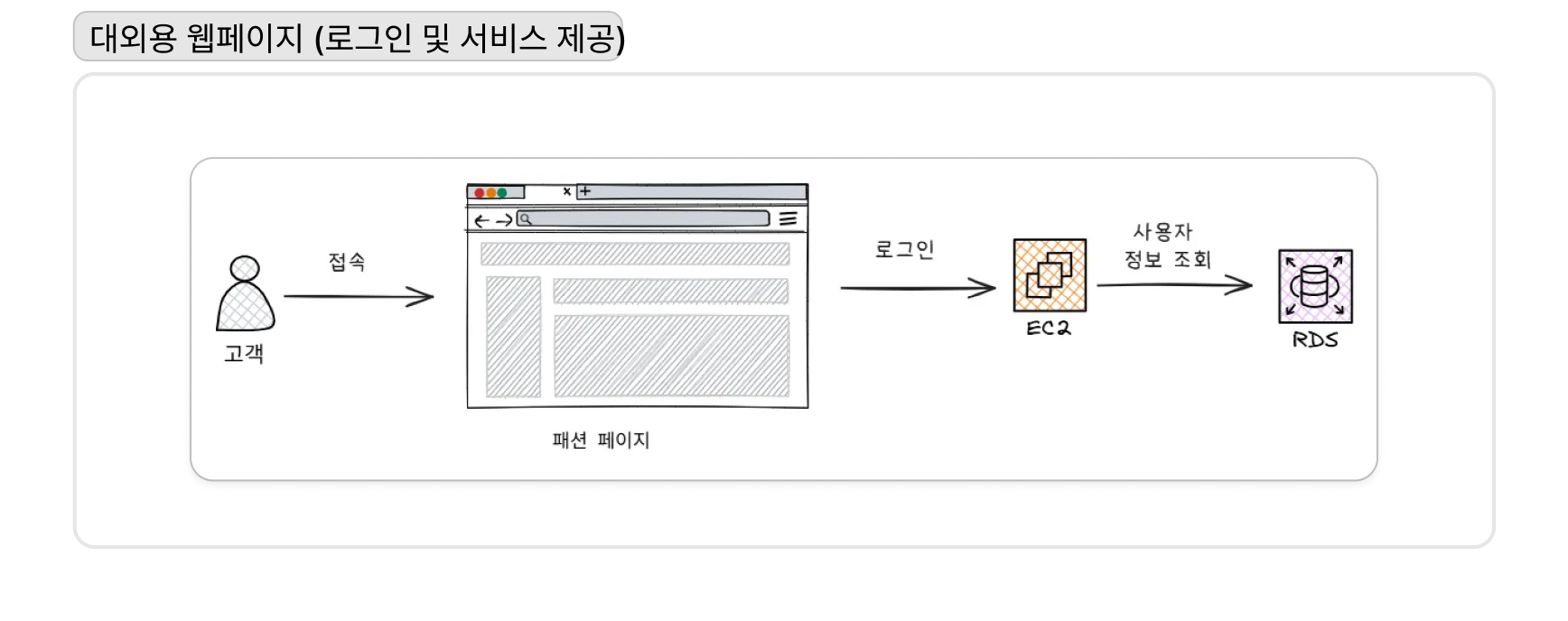
 반면, 실제 쇼핑이 이뤄지는 동적 패션 포털(WebB)은 트래픽 변동에 유연하게 대응하기 위해 Application Load Balancer(ALB)와 EC2 Auto Scaling Group을 활용했다. 특히 데이터베이스는 고가용성을 위해 Amazon RDS for MySQL을 Multi-AZ로 구성하여 장애 발생 시에도 서비스 중단을 최소화했다.
반면, 실제 쇼핑이 이뤄지는 동적 패션 포털(WebB)은 트래픽 변동에 유연하게 대응하기 위해 Application Load Balancer(ALB)와 EC2 Auto Scaling Group을 활용했다. 특히 데이터베이스는 고가용성을 위해 Amazon RDS for MySQL을 Multi-AZ로 구성하여 장애 발생 시에도 서비스 중단을 최소화했다.
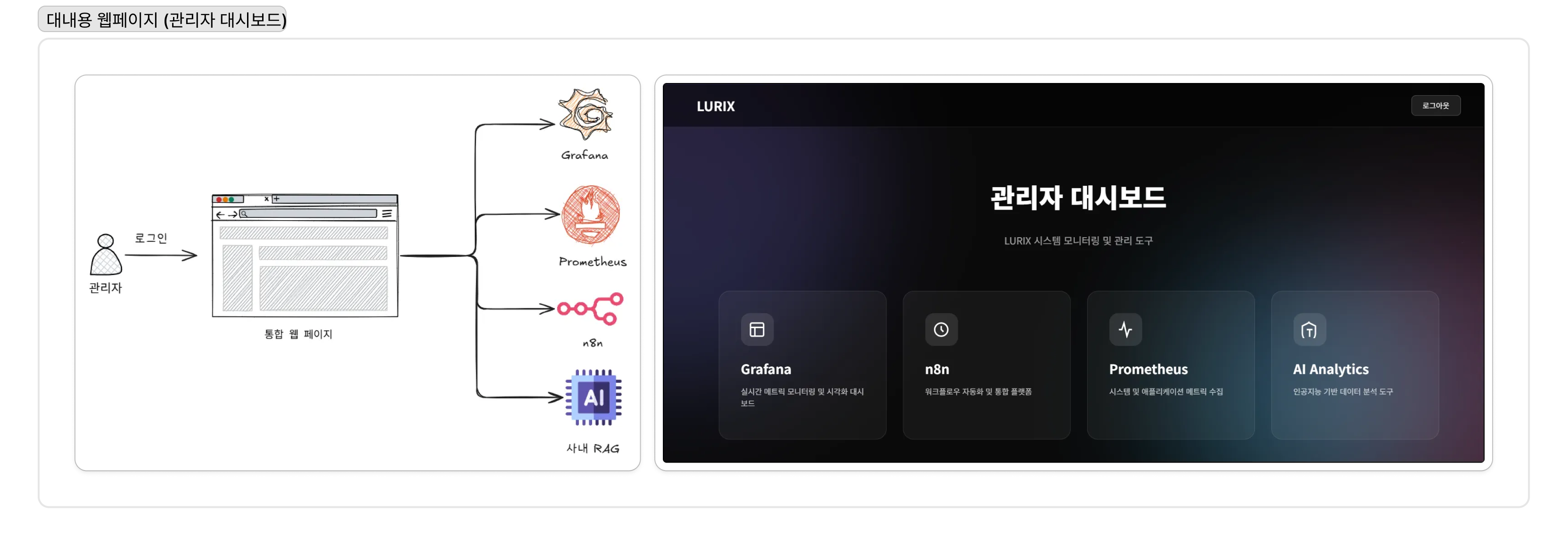
 한편, 대내용 업무 서비스인 통합 대시보드는 보안을 최우선으로 고려했다. Grafana, Prometheus, n8n과 같은 운영 도구들은 모두 외부 접근이 차단된 Private Subnet에 배치하고, 허가된 관리자만이 AWS Systems Manager Session Manager를 통해 안전하게 접근하도록 설계하여 내부 시스템의 보안 경계를 명확히 했다.
한편, 대내용 업무 서비스인 통합 대시보드는 보안을 최우선으로 고려했다. Grafana, Prometheus, n8n과 같은 운영 도구들은 모두 외부 접근이 차단된 Private Subnet에 배치하고, 허가된 관리자만이 AWS Systems Manager Session Manager를 통해 안전하게 접근하도록 설계하여 내부 시스템의 보안 경계를 명확히 했다.
 웹서비스의 전체 아키텍처를 되돌아보면, 다음과 같이 정리할 수 있었다.
웹서비스의 전체 아키텍처를 되돌아보면, 다음과 같이 정리할 수 있었다.
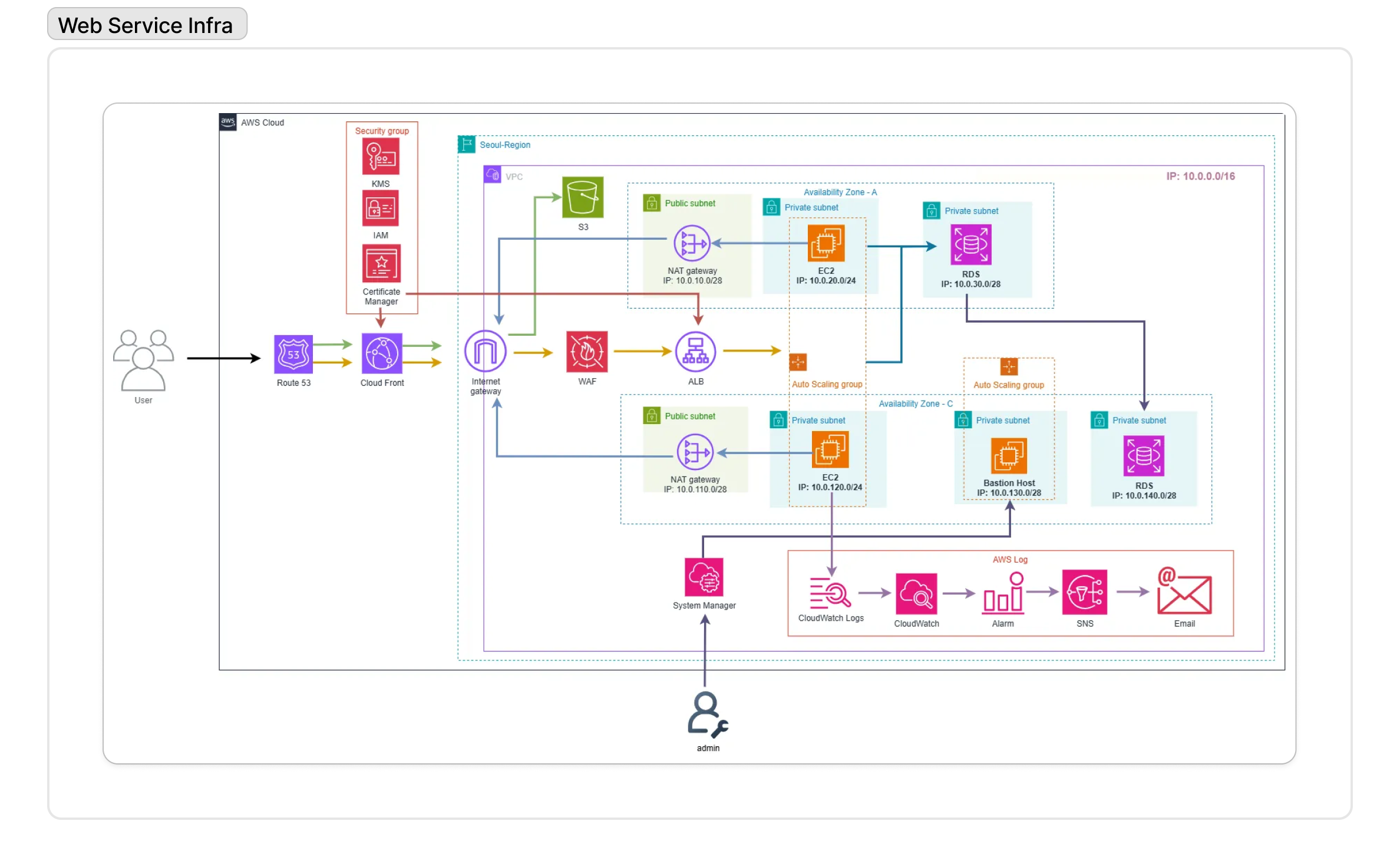
두 번째 축은 모든 데이터 활용의 근간이 될 중앙 데이터 레이크(Data Lake) 구축이었다.
Amazon S3를 중심으로, 흩어져 있던 모든 시스템 로그(VPC, CloudTrail, WAF 등)를 자동으로 수집하는 구조를 설계했다. 이때, 로그의 성격에 따라 수집 전략을 이원화했다.
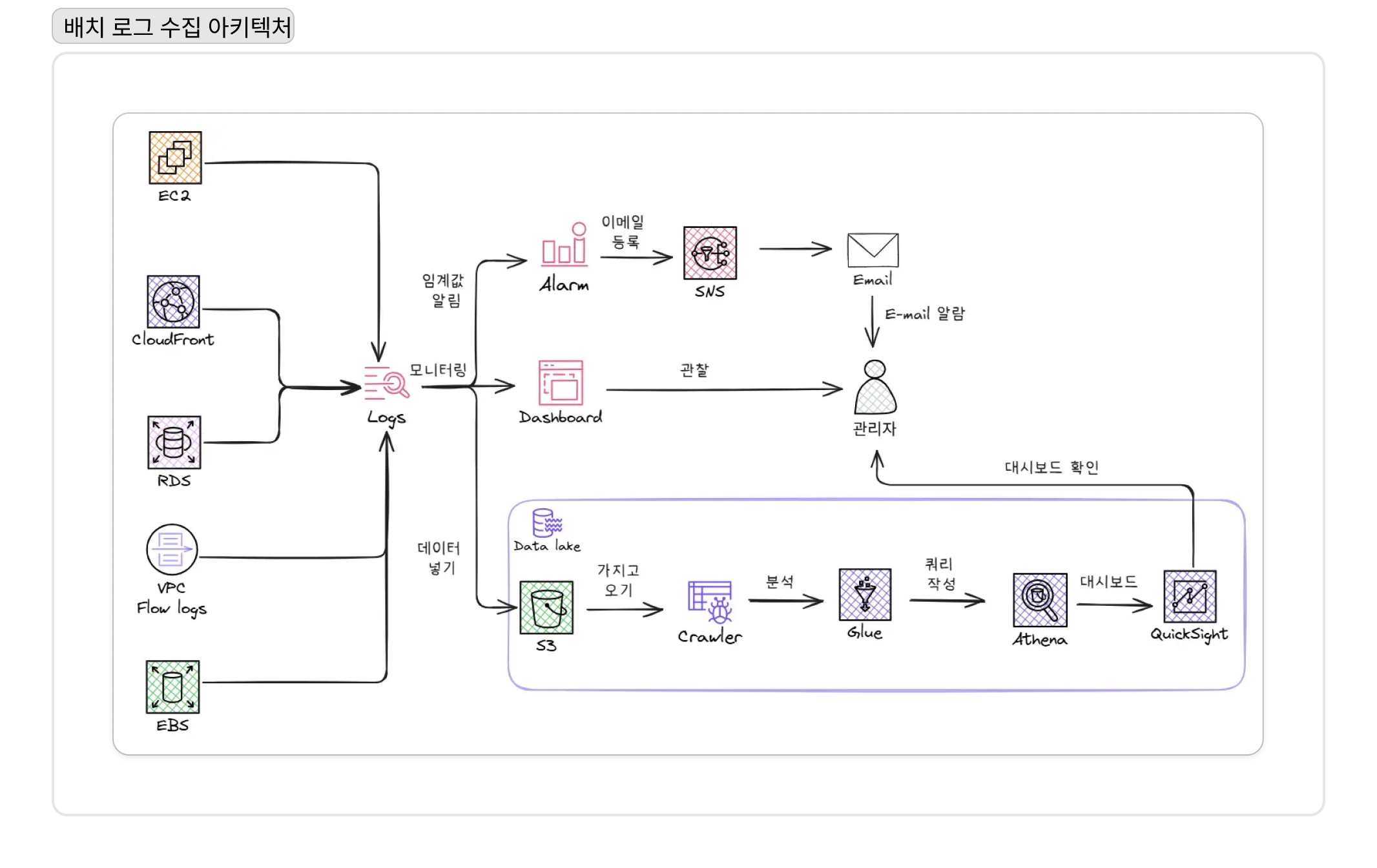
VPC Flow Logs, ALB 액세스 로그와 같이 주기적인 분석이 중요한 데이터는 각 서비스에서 S3로 직접 전송하는 배치(Batch) 파이프라인을 구성하여 비용 효율을 높였다.
 반면, WAF 로그처럼 즉각적인 보안 위협 탐지가 필요한 데이터는 Kinesis Data Firehose를 통해 실시간 스트리밍 파이프라인을 구축하여 지연 시간을 최소화했다.
반면, WAF 로그처럼 즉각적인 보안 위협 탐지가 필요한 데이터는 Kinesis Data Firehose를 통해 실시간 스트리밍 파이프라인을 구축하여 지연 시간을 최소화했다.
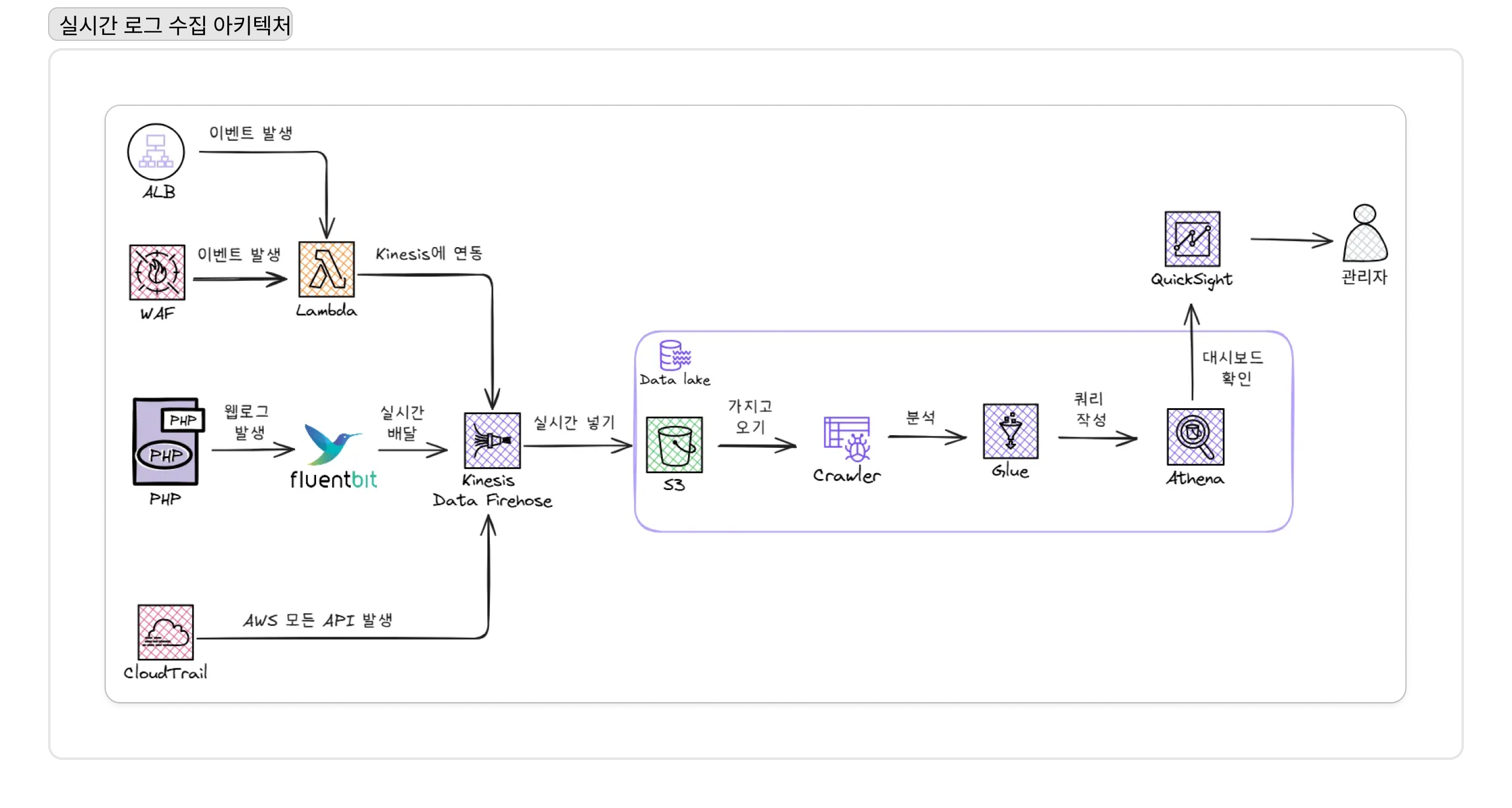 하지만 단순히 데이터를 모으기만 해서는 ‘데이터 늪(Data Swamp)‘에 불과했다. 이 데이터를 실질적으로 활용 가능하게 만들기 위해 AWS Glue를 도입했다. S3에 쌓인 다양한 형식의 로그들을 Glue Crawler가 주기적으로 스캔하여 스키마를 자동으로 감지하고, 이를 중앙 메타데이터 저장소인 Glue Data Catalog에 등록하도록 했다. 이 과정을 통해 비정형 데이터가 정형화된 테이블처럼 관리되기 시작했고, 우리는 Amazon Athena를 통해 표준 SQL로 즉시 데이터를 쿼리하고 분석할 수 있는 환경을 갖추게 되었다. 데이터가 비로소 진정한 ‘자산’이 되는 순간이었다.
하지만 단순히 데이터를 모으기만 해서는 ‘데이터 늪(Data Swamp)‘에 불과했다. 이 데이터를 실질적으로 활용 가능하게 만들기 위해 AWS Glue를 도입했다. S3에 쌓인 다양한 형식의 로그들을 Glue Crawler가 주기적으로 스캔하여 스키마를 자동으로 감지하고, 이를 중앙 메타데이터 저장소인 Glue Data Catalog에 등록하도록 했다. 이 과정을 통해 비정형 데이터가 정형화된 테이블처럼 관리되기 시작했고, 우리는 Amazon Athena를 통해 표준 SQL로 즉시 데이터를 쿼리하고 분석할 수 있는 환경을 갖추게 되었다. 데이터가 비로소 진정한 ‘자산’이 되는 순간이었다.
세 번째 축은 정보 사일로를 근본적으로 해결할 지능형 RAG(검색 증강 생성) 시스템 구현이었다.
PDF나 구글 드라이브에 잠자고 있던 방대한 업무 지식을 활용하기 위해 Amazon Kendra를 도입했다. Kendra의 강력한 커넥터 기능을 활용해 S3, Google Drive, Gmail 등 여러 데이터 소스를 연결하여 통합된 지식 인덱스를 생성했다. 그 위에 AWS Lambda를 이용해 정교한 질의응답 파이프라인을 설계했다. 사용자가 웹 인터페이스를 통해 질문을 던지면, Lambda 함수는 먼저 Kendra에 질의하여 가장 관련성 높은 문서의 핵심 구절을 검색(Retrieval)한다. 그런 다음, 검색된 내용을 신뢰할 수 있는 근거 자료로 삼아 Amazon Bedrock의 Claude 3 모델에게 전달하여, 자연스럽고 맥락에 맞는 답변을 생성(Augmented Generation)하도록 요청했다.
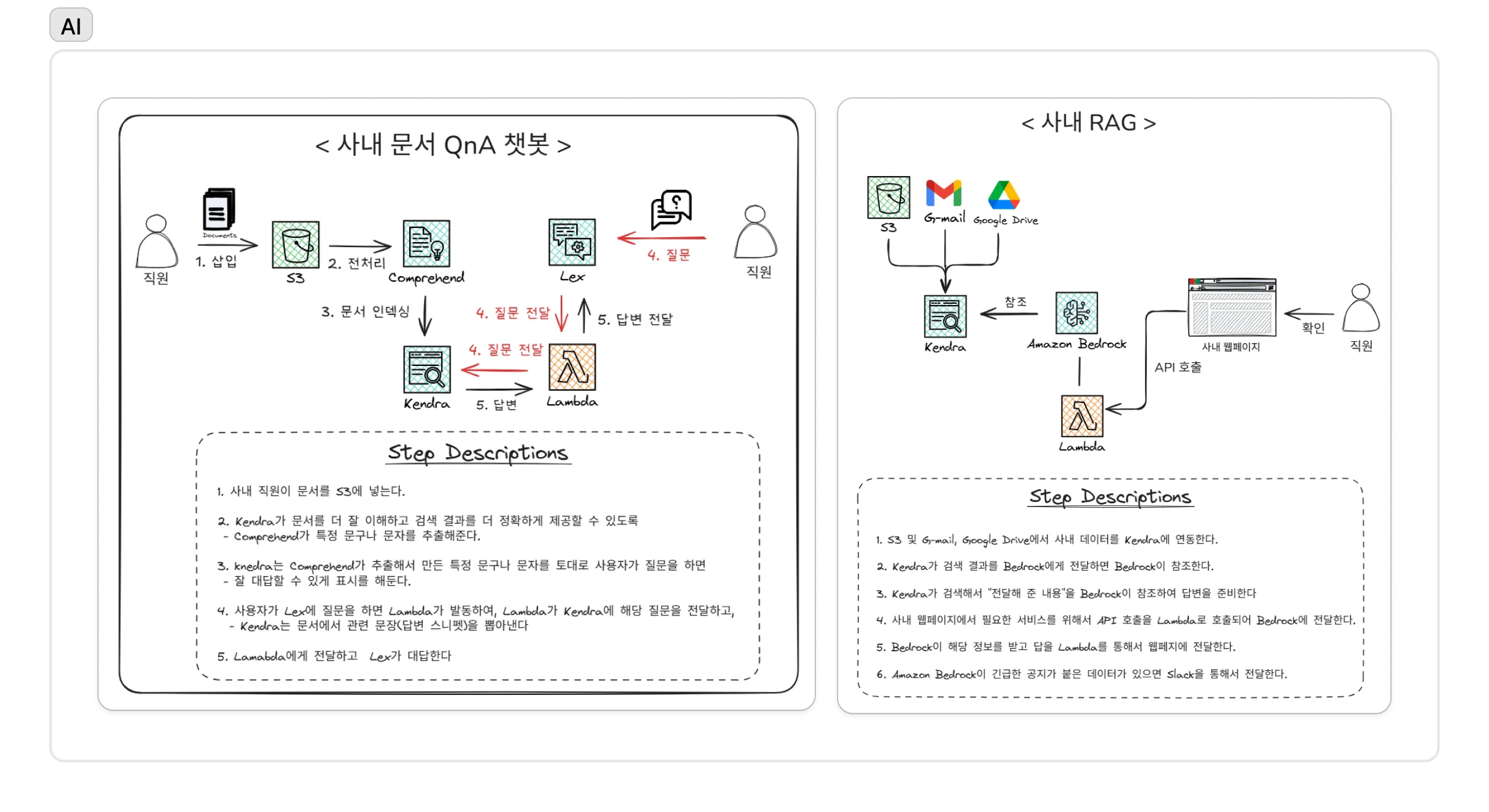 이 RAG 파이프라인 덕분에 사용자들은 복잡한 검색 과정 없이 자연어 질문 하나만으로 가장 정확한 정보와 그 출처까지 얻을 수 있게 되었다.
이 RAG 파이프라인 덕분에 사용자들은 복잡한 검색 과정 없이 자연어 질문 하나만으로 가장 정확한 정보와 그 출처까지 얻을 수 있게 되었다.
마지막 네 번째 축은 이 모든 시스템의 안정성을 책임질 관찰 가능성(Observability) 및 운영 자동화(ITOps) 플랫폼이었다.
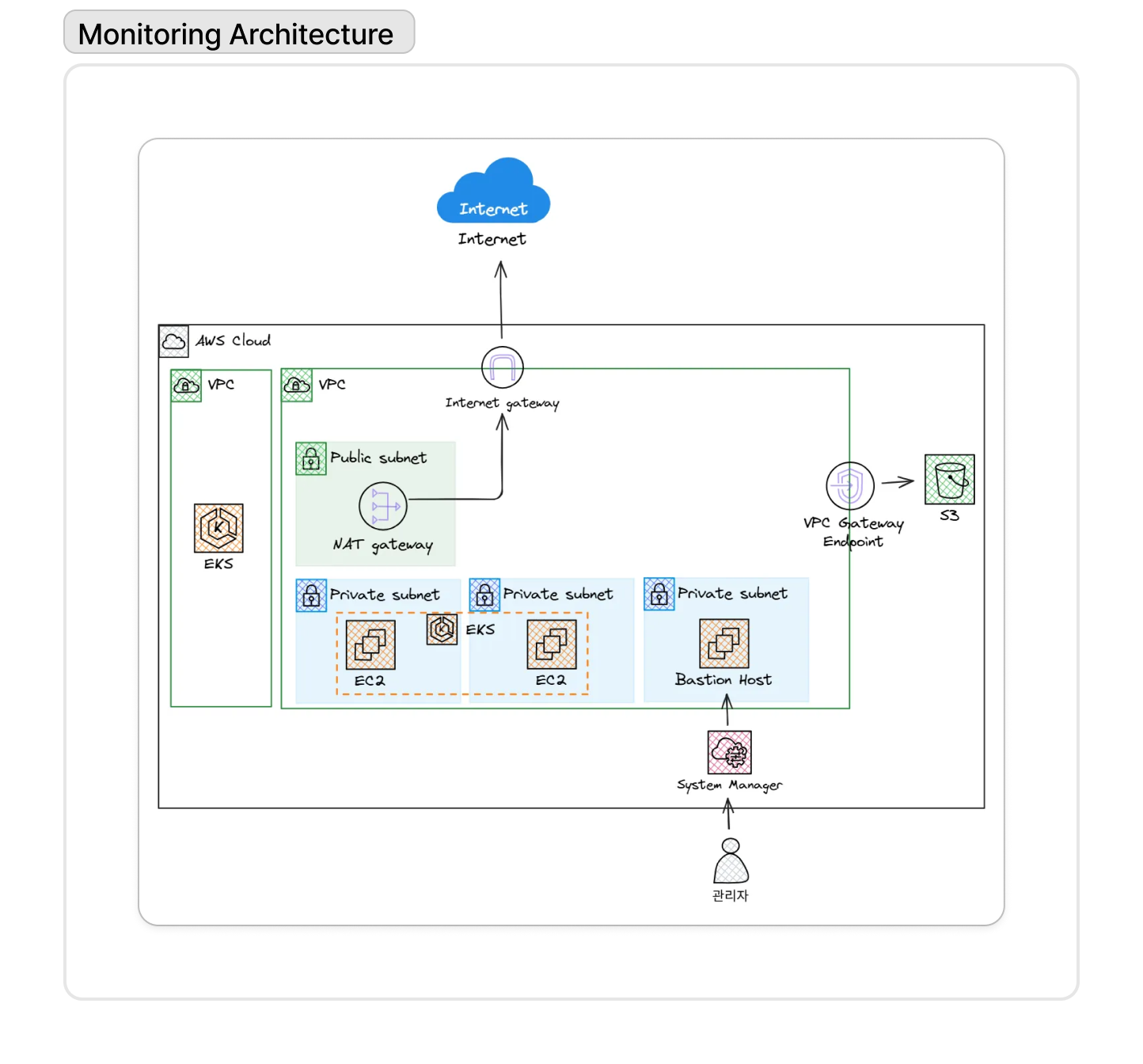
마이크로서비스 및 운영 도구를 실행하기 위한 기반으로 Amazon EKS(Elastic Kubernetes Service) 클러스터를 구축했다. 컨테이너 환경의 복잡한 로그와 메트릭을 효과적으로 관리하기 위해, 로그는 Fluent Bit를 사이드카나 DaemonSet 형태로 배포하여 수집하고, 시스템 메트릭은 Prometheus를 통해 수집했다. 수집된 모든 데이터는 Grafana를 통해 시각화하여 시스템 상태를 한눈에 파악할 수 있는 통합 대시보드를 구축했다.
 여기서 더 나아가, 반복적인 장애 대응 작업을 자동화하기 위해 n8n을 도입했다. 예를 들어, Grafana에서 특정 Pod의 CPU 사용률이 임계치를 초과하여 알림이 발생하면, 이 알림이 Webhook을 통해 n8n 워크플로우를 자동으로 트리거한다. 그러면 n8n은 미리 정의된 시나리오에 따라 담당자에게 슬랙 알림을 보내는 등의 조치를 자동으로 수행한다.
여기서 더 나아가, 반복적인 장애 대응 작업을 자동화하기 위해 n8n을 도입했다. 예를 들어, Grafana에서 특정 Pod의 CPU 사용률이 임계치를 초과하여 알림이 발생하면, 이 알림이 Webhook을 통해 n8n 워크플로우를 자동으로 트리거한다. 그러면 n8n은 미리 정의된 시나리오에 따라 담당자에게 슬랙 알림을 보내는 등의 조치를 자동으로 수행한다.
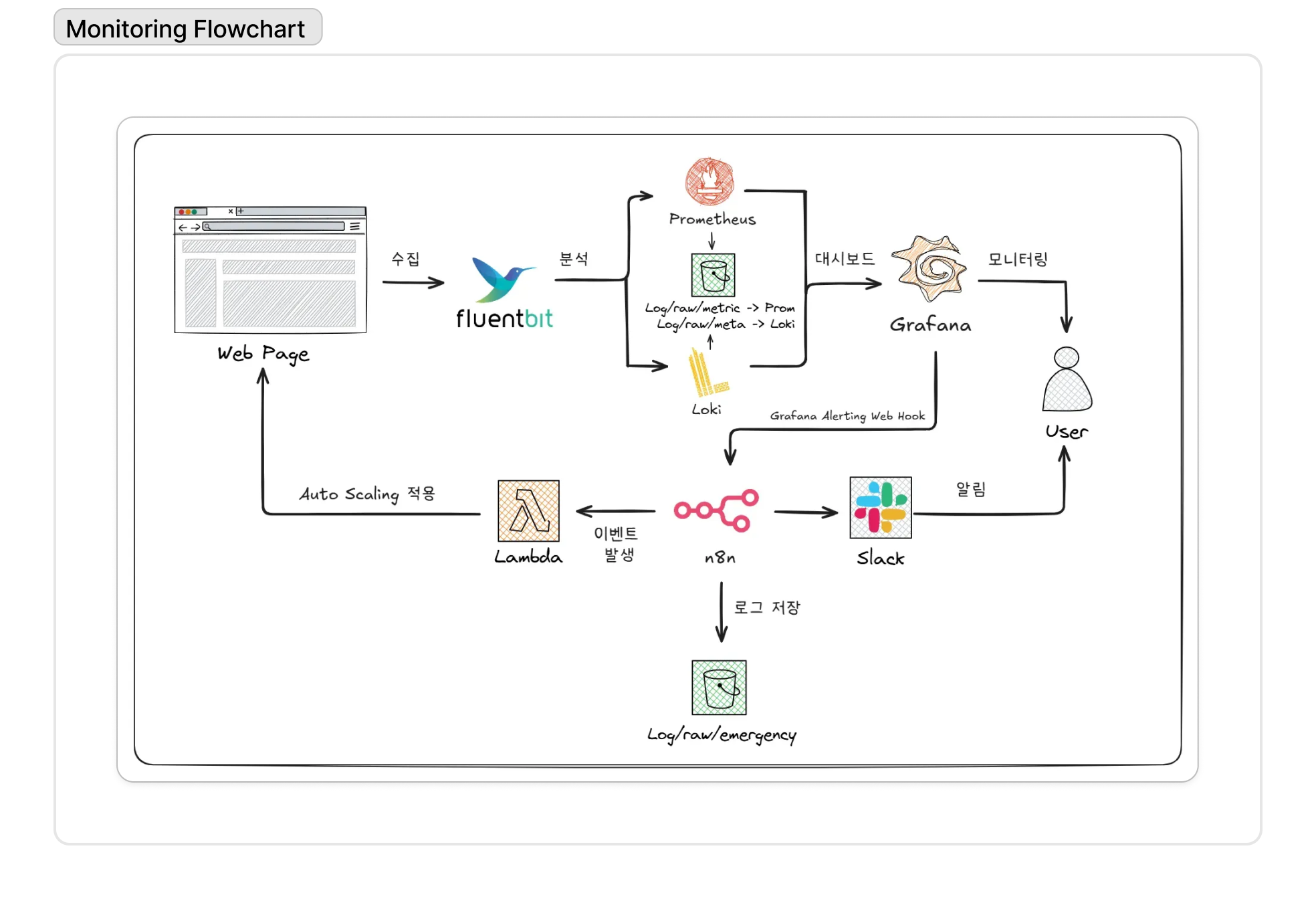 이는 단순 모니터링을 넘어, 운영을 지능화하고 엔지니어의 개입을 최소화하는 AIOps의 실질적인 구현이었다.
이는 단순 모니터링을 넘어, 운영을 지능화하고 엔지니어의 개입을 최소화하는 AIOps의 실질적인 구현이었다.
그래서 무엇을 얻었는가
결과적으로, 물리적, 논리적으로 완전히 분리되어 있던 전사 데이터 자산을 하나의 유기적인 플랫폼으로 통합하는 데 성공했다. 이는 단순히 기술적인 완성을 넘어, 조직 전체의 정보 접근성과 운영 효율성을 한 단계 끌어올리는 실질적인 변화를 가져왔다. 직원들은 RAG 시스템을 통해 필요한 정보를 즉시 얻을 수 있게 되었고, 엔지니어들은 중앙 데이터 레이크와 관찰 가능성 플랫폼을 통해 장애 분석과 대응 시간을 획기적으로 줄일 수 있었다. 비즈니스 관점에서도 효율성이 높아지고 전반적인 서비스 안정성이 개선되는 뚜렷한 성과를 확인할 수 있었다.
무엇보다 이번 프로젝트는 내게도 큰 성장을 가져다주었다. AWS 기반의 아키텍처 설계부터 데이터 통합 및 AI 기반 질의응답 시스템 구축까지 전 과정을 경험하며, 기술적인 부분뿐 아니라 전사적 관점에서 정보 시스템의 효율성과 안정성을 높이는 방법에 대한 깊은 통찰을 얻을 수 있었다. ‘아키텍트’의 역할이 개별 서비스를 잘 사용하는 것을 넘어, 데이터 거버넌스, 보안, 비용, 확장성 등 비기능적 요구사항까지 고려하며 전체 시스템의 청사진을 그리는 것임을 체감했다. 이 고되고 즐거웠던 여정을 통해 얻은 가장 큰 깨달음은 결국 기술은 사용자에게 실제로 가치를 제공할 수 있을 때 비로소 그 의미가 있다는 사실이었다. 앞으로도 기술을 활용해 실질적인 문제를 해결하고 가치를 제공하는 일을 지속하고 싶다는 다짐을 다시 한번 새기게 되었다.
GitHub 계정으로 로그인하여 댓글을 남겨보세요. GitHub 로그인
댓글 시스템 설정이 필요합니다
GitHub Discussions 기반 댓글 시스템을 활성화하려면:
- Giscus 설정 페이지에서 설정 생성
- GISCUS_SETUP_GUIDE.md 파일의 안내를 따라 설정 완료
- Repository의 Discussions 기능 활성화
Repository 관리자만 설정할 수 있습니다.